基因组测序技术每年提供数千个新的植物基因组。在农业中,研究人员将这些基因组信息与观测数据(测量各种植物性状)相结合,以确定遗传变异与作物性状(如种子数、对真菌感染的抵抗力、水果颜色或风味)之间的相关性。
然而,对遗传变异如何在分子水平影响基因活性的了解相当有限。这种知识差距阻碍了通过组合已知功能的特定基因变体来培育提高质量并减少负面环境影响的“智能作物”。
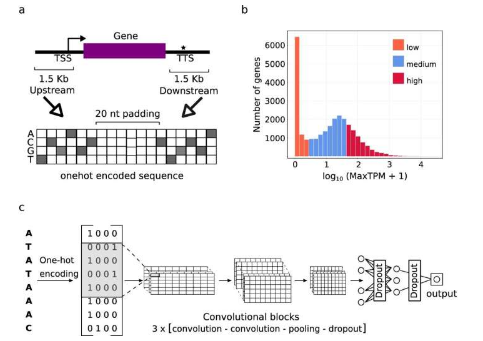
来自 IPK 莱布尼茨研究所和于利希研究中心 (FZ) 的研究人员在应对这一挑战方面取得了重大突破。由 Jedrzej Jakub Szymanski 博士领导的国际研究团队在来自不同植物物种的庞大基因组信息数据集上训练了可解释的深度学习模型(人工智能算法的一个子集)。
“这些模型不仅能够根据序列准确预测基因活性,还能查明哪些序列部分有助于这些预测,”IPK 网络分析和建模研究小组的负责人解释道。研究人员应用的人工智能技术类似于计算机视觉中使用的技术,涉及识别图像中的面部特征并推断情绪。
与之前基于统计富集的方法相比,研究人员将序列特征的识别与数学模型框架中 mRNA 拷贝数的确定相结合,该数学模型经过训练,考虑了基因模型结构和序列同源性的生物信息,从而基因进化。
“我们对它的有效性感到非常惊讶。经过几天的训练,我们重新发现了许多已知的调控序列,并发现大约 50% 的识别特征是全新的。这些模型可以很好地泛化到它们没有接受过训练的植物物种中,使得它们对于分析新测序的基因组很有价值,”Szymanski 博士说。